
The Poorly Design Lastlog Linux Sparse Files

I am writing this post at 4:20 AM and starving, since I am also struggling to adjust my sleeping schedule again, totally bad idea. So let me get my snacks (including mie kuah indomie rasa ayam bawang) to proceed while accomplishing this rather technical and sophisticated post. Surprisingly, this is gonna be my first computer operating system post, ever.

I am not a geek, yet I have been casually studying Linux for almost 8 years, and 4 years bachelor of computer engineering and I had no idea about the term 'sparse file' until I coincidentally found it in Ubuntu 22.04 while debugging the VM workload that was occurred at the company where I am currently working, Tokopedia and GoTo Logistics.

Though, nowadays we have been surrounded by cloud-native workload such as container orchestrator: Kubernetes that is very efficient in terms of cost and technical practice, however, we are still managing Virtual Machines as our main workload. In my opinion, managing VMs are superb, impractical for some reasons. We may find the tradeoff to maintain every single thing manually, such as the multi-vendor strategy to create VM's image, including the attach/detach disk, backup/restore some files and folders and more.
And now, the mystery is happening.
Caught the mystery
It started when there is something strange in our Virtual Machine and it led approximately 20 minutes delay time process during the /var/log backup process. It was negatively impacting the overall process, such as the increasing of CPU utilisation which made every process heavier, and led a delayed additional dependency process and main app booting.
After researching for almost 2 months (Lazy mode 😹), I found that /var/log/lastlog which was having a 1.2 TB size, not an actual disk, but a sparse file's metadata. The actual size of this sparse file is merely around 64KB at that time. It's almost fake.

#----------------------#
# To see metadata size #
#----------------------#
# ls -lah /var/log/lastlog
-r-------- 1 root root 1.2T Jan 28 4:26 /var/log/lastlog
#----------------------------#
# To see actual size on disk #
#----------------------------#
# du -sh /vat/log/lastlog
64K /var/log/lastlog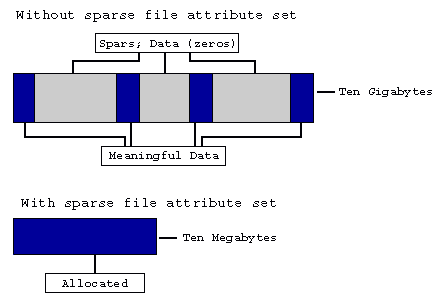
Sparse files offer a more efficient way to store and handle large files with a lot of empty space. Unlike regular files, they only use actual disk space for the data written, avoiding unnecessary storage allocation and reducing unneeded read/write operations. This results in significant space savings, reduced system burden, and quicker processing times. However, they have their own limitations and may not be the best fit for all use cases. The choice between sparse and regular files really comes down to understanding your specific needs and how best to meet them.
Our log backup script was using rsync to backup the /var/log data, and since rsync has its own limitation to handle a sparse file, even though it has additional flags such as --sparse or -S, it would work when the sparse file's size is MB or GB, yet the rsync process is still taking too long time to map this 1.2 TB sparse file, it led the system to compute 1.2 TB and dramatically increased CPU utilisation over time. The nightmare of rsync and lastlog meeting, and I was crying at the corner.
What is lastlog

The above illustration simply describes the lastlog.
The importance of the lastlog file depends on the context of system administration and security. In a nutshell, lastlog keeps track record of the last login time and session of all users in the system.
It is quite important for Auditing and Security which provide crucial information in timing the use of resources, diagnosing potential unauthorised access, or tracking user access for auditing purposes. Other than that, forensics, In cases of security breaches, lastlog can provide vital clues for system forensics.

However, I am still not pretty sure, why did they design it with sparse file. Why on earth they poorly design the database by using a sparse file. It is something that I have asked to google several times, but I didn't see the conclusion. I mean, I understood the concept of sparse files, but I didn't get it when they created lastlog with a sparse file completely. After researching on why does the /var/log/lastlog file appear so huge (in GB or sometime in TB) sparse file on 64-bit machines is that space is provisioned in advance for every possible user ID. Given that there are approximately 2^32 users and each login record uses 256 bytes, the total comes to around 1.2 TB - give or take. And that's it. There is no background or behind the scene.
For example, If somebody tried to login, lastlog will write the info into the sparse file, it took 256 bytes only out of 1.2 terra bytes of empty space. That was efficient and inefficient at the same time. Why do they create a sparse file, while we can still use a regular file. It won't hurt the performance wise, and we can rotate it and compress it, just like a regular log file 😐. I mean why did they generate a very large file metadata size by 1.2 TB.🤯 Like they can create a lastlog binary to read a compressed file and aggregate it is also possible for the alternative.
Is it because of we need to achieve an efficient energy saving? Less Computation power? Green energy? Are you sure about that😂.
I am aware, that disk efficiency of sparse file is good for large and scattered UID logged in users. Suppose we want to record data for user logins. Assume that the user ID is related to the position of their data in the file. This means if we have a user so-called "Rafi Ahmad" with an ID of 10,000, his data will be placed at the 10,000th position in the file.
Now, we only have 100 users, but their IDs are scattered in a wide range. The highest user ID is 10,000. It could be random and scattered like 1, 7, 100, 107, 200, 10000 so on and so forth until 100 users in total.
If you use a regular file to store this data, you need to create a file large enough to accommodate 10,000 entries since the user with the highest ID is 10,000. In regular files, each character (whether it's filled with real data or it's a null character represented by '0') occupies disk space.
Contrarily, in sparse files, if there are sections filled with null characters, the filesystem only records the metadata about where these null characters are located and how many there are, but does not consume any actual disk space for storing these null characters. But since we only have 100 users, 9,900 entries in that file are going to be empty. Thus, sparse file is more storage efficient compared to regular file.
But, in real situations, even a large-scale company will not have login users more than 1000 users in a single machine. 😂
Implications
It has been implicated several commands in the apps or tools that touch this file. It impacted at every tool that has copy/archive/extract capability, it needs to have an "special" understanding of copying sparse files as well. Such as cp, mv, rsync, zip, tar, unzip, untar, unrar and more.
If we didn't define the handling of sparse files, it would directly copy the metadata size onto the disk, instead of using the actual size, which could be very risky. For instance, if we were to copy a 1.2TB sparse file that actually uses 64KB on the disk, without the appropriate handling, it would copy 1.2TB onto the disk instead of just copying 64KB.
The fact that handling sparse files using flags is not sufficient for rsync. I attempted to run rsync on the 1.2 TB file and due to the natural large size of a sparse file, it still had a mapping duration that was taking forever and even caused hanging. Therefore, there are still limitations to sparse file handling. So sad.
The Workaround
The workaround is using other than rsync, we can just move it with mv and cp.
And it turns out retained the sparse file and the actual size without any sparse handling flag. Magical.

Final Thoughts
Sparse files are like smart files that only take up space when they need to. Imagine a book that only has pages when you write on it. This way, they save a lot of room and work faster compared to regular files, which are like normal books that have all pages, filled or not. But sparse files also have limitations and may not be suitable for all situations, just like the legacy lastlog file. Because It cannot be synced with rsync, it would take forever. And finally, this requires a different backup scripts to hack all of this. So annoying, isn't it?




